Disclaimer:
This article doesn't aim to be a comprehensive tutorial on HTTP caching strategies and their workings.
There are many sources available that covers that.
Instead, this post is geared towards developers who have some level of experience and provides a reference point for how they can make use of caching headers.
Parts of this post are technical, but I've tried to simplify complex concepts with ELI5 explanations and visualizations (because that's how I learn best!)
This article does a better job of explaining how caches work in more detail and depth if you want to learn more about the topic.
Introduction
In traditional web applications that are not using a Single-Page Application (SPA) architecture, HTML assets have a crucial role in determining performance.
For instance, if an SVG image takes 100ms to download and process into the HTML of a page, it will cause a corresponding 100ms delay for all other components.
Illustrating the Problem
To highlight the issue, let's consider a scenario where our server doesn't have a working caching strategy configured via HTTP Response Headers.
In reality, omitting the Cache-Control response header doesn't turn off HTTP caching.
In a recent article on web.dev, it was pointed out that it leaves browsers to make an educated guess about the most appropriate caching behavior for a particular type of content.
When a user first visits a website, the browser retrieves all the necessary resources required to display the page properly. Consider, for instance, an SVG icon: Scenario: A user navigates to the homepage of the site via the path 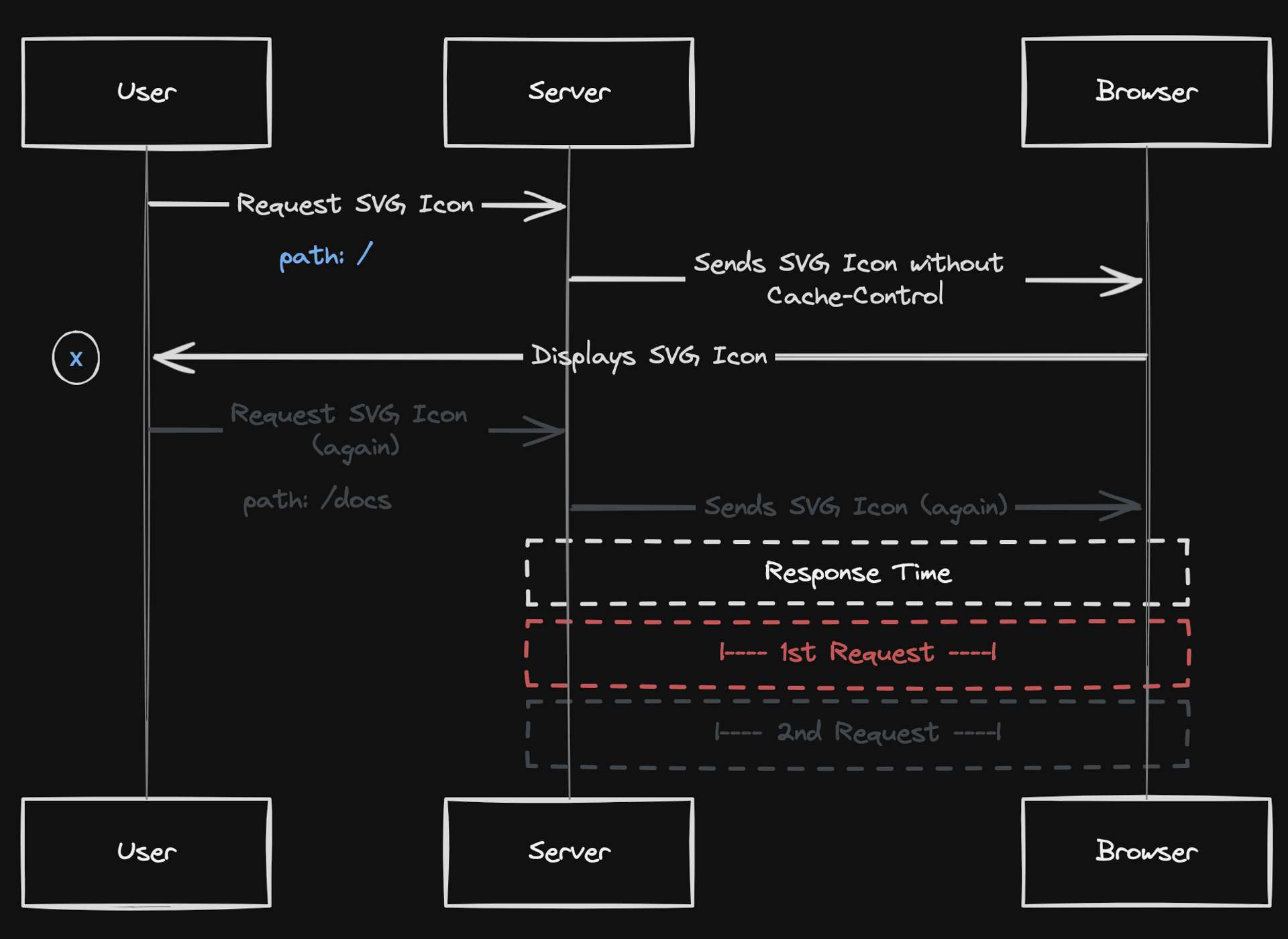
/.
As the user navigates through the site, clicking on various links leading to different paths within the site, the browser repeatedly fetches and processes the same SVG icon for each new page. Scenario: A user clicks on a link on the site and navigates to path 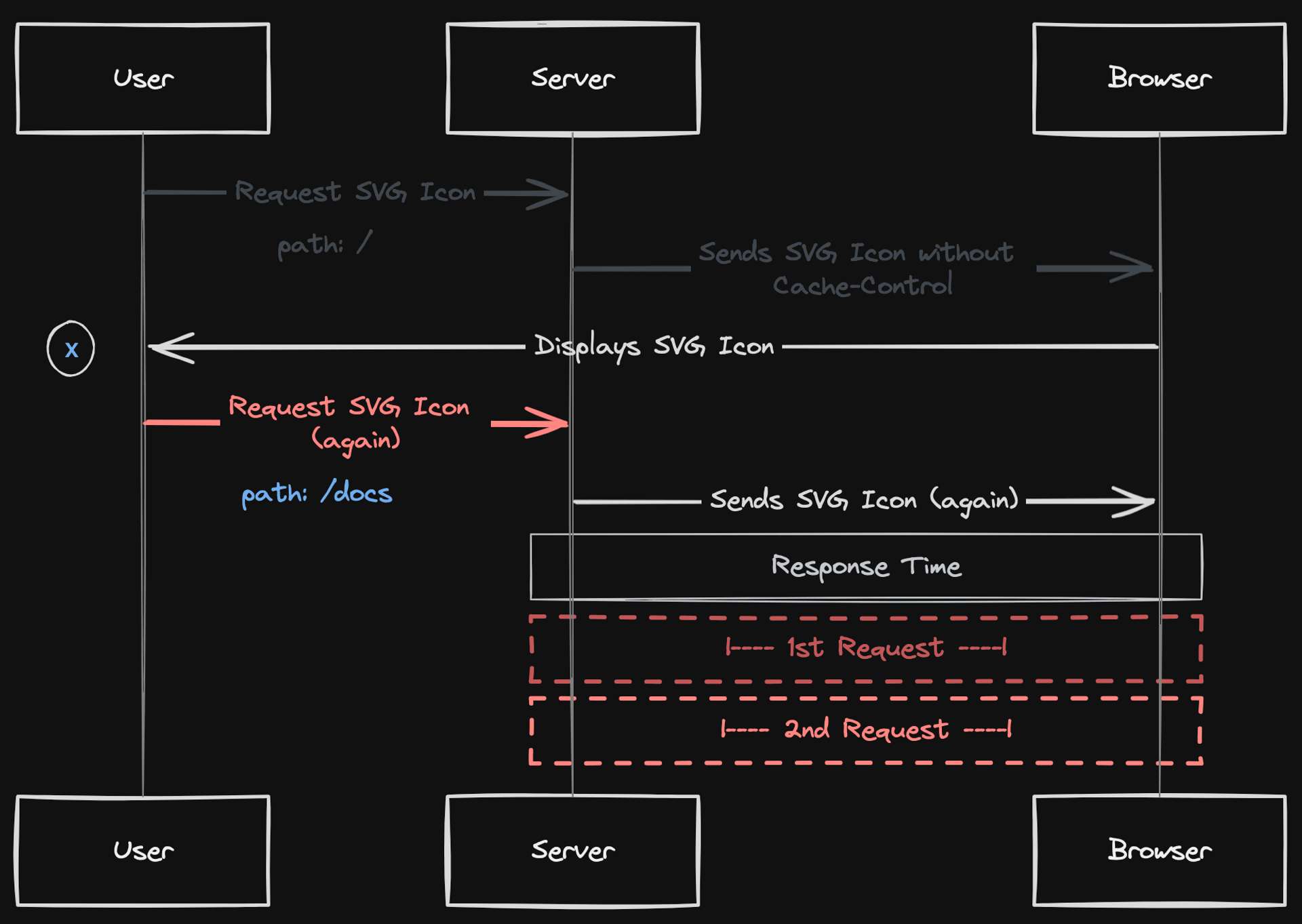
/docs.
This means that the same SVG icon is being redundantly fetched and processed multiple times as the user explores the site, which can lead to unnecessary network requests and processing time.
I hope this helps illustrate what we're trying to solve with a caching strategy.
Caching Explained
In computing, the term caching refers to storing frequently accessed data temporarily in a faster memory or storage.
HTTP Caching is a technique used to improve website performance and can be implemented by the client, server, an intermediate source such as a CDN, or any combination of these.
When it comes to websites, this is where the Cache-Control header comes into play. It's a key player defined in the HTTP/1.1 Spec that helps us manage how our resources are cached.
Browser Cache
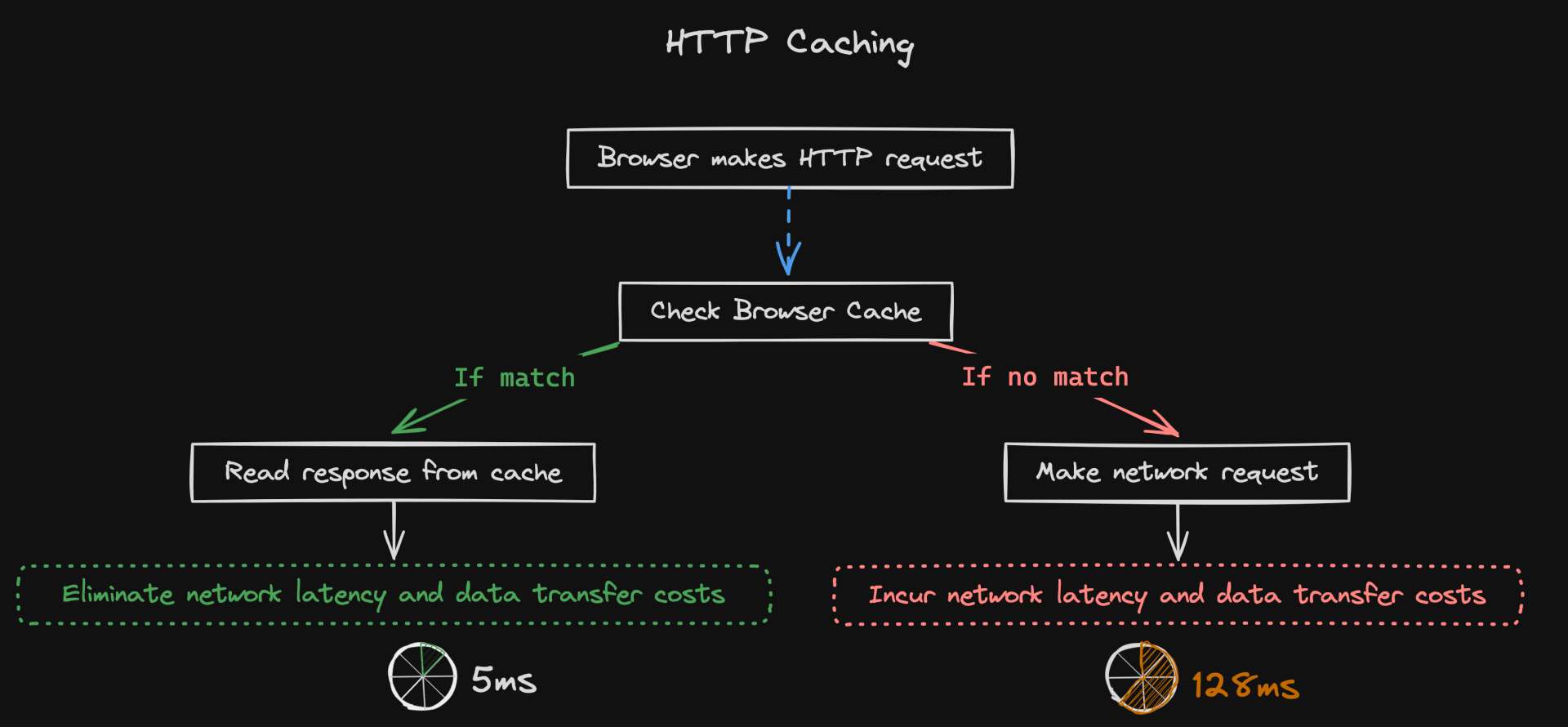
Browser caching is the process of storing web page files temporarily, such as images, stylesheets, and JavaScript files, on a user’s local device/browser.
This eliminates the need to make a network request each time these resources are required, speeding up load time on subsequent visits.
Private & Shared Caches
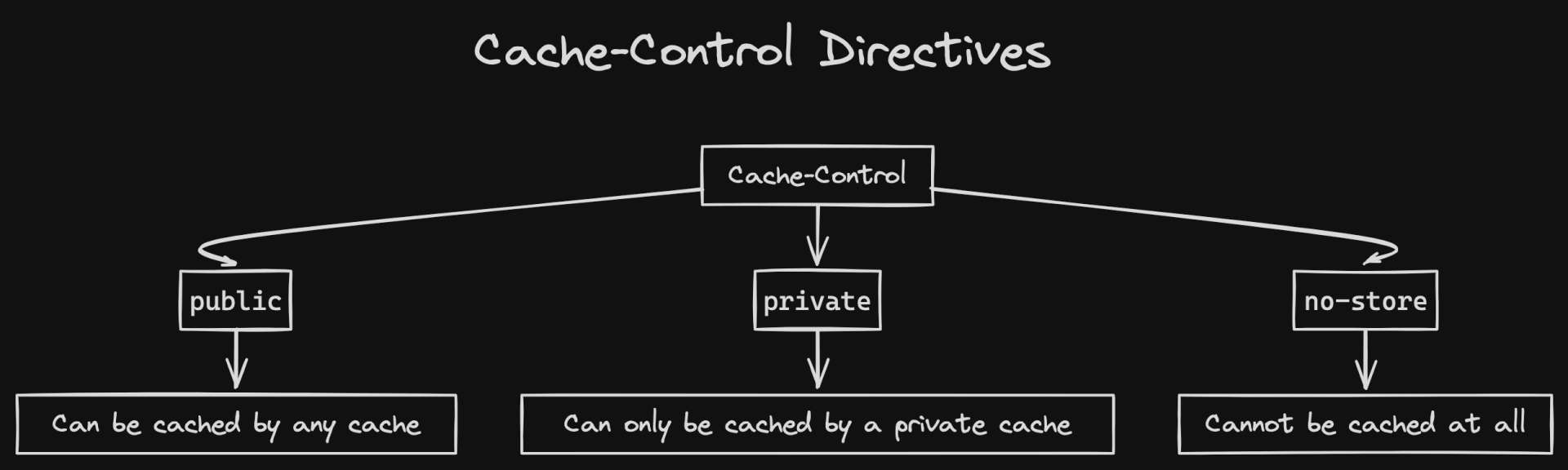
In addition to caching in your browser, if your content is behind a CDN then your cache-control headers influence how the CDN caches your content on the edge.
Browser cache is referred to as a private cache, while a CDN cache is referred to as a shared cache. The cacheability of a resource is set using the directives below:
| Directive | Description |
|---|---|
public | Any cache may store the response, including a CDN. |
private | The response is intended for a single user and should only be stored by the browser cache. |
no-store | Should not be stored on any cache. |
ELI5 Explanation
Let's use a library as an analogy:
__
public: This is like a book in the public section of the library.
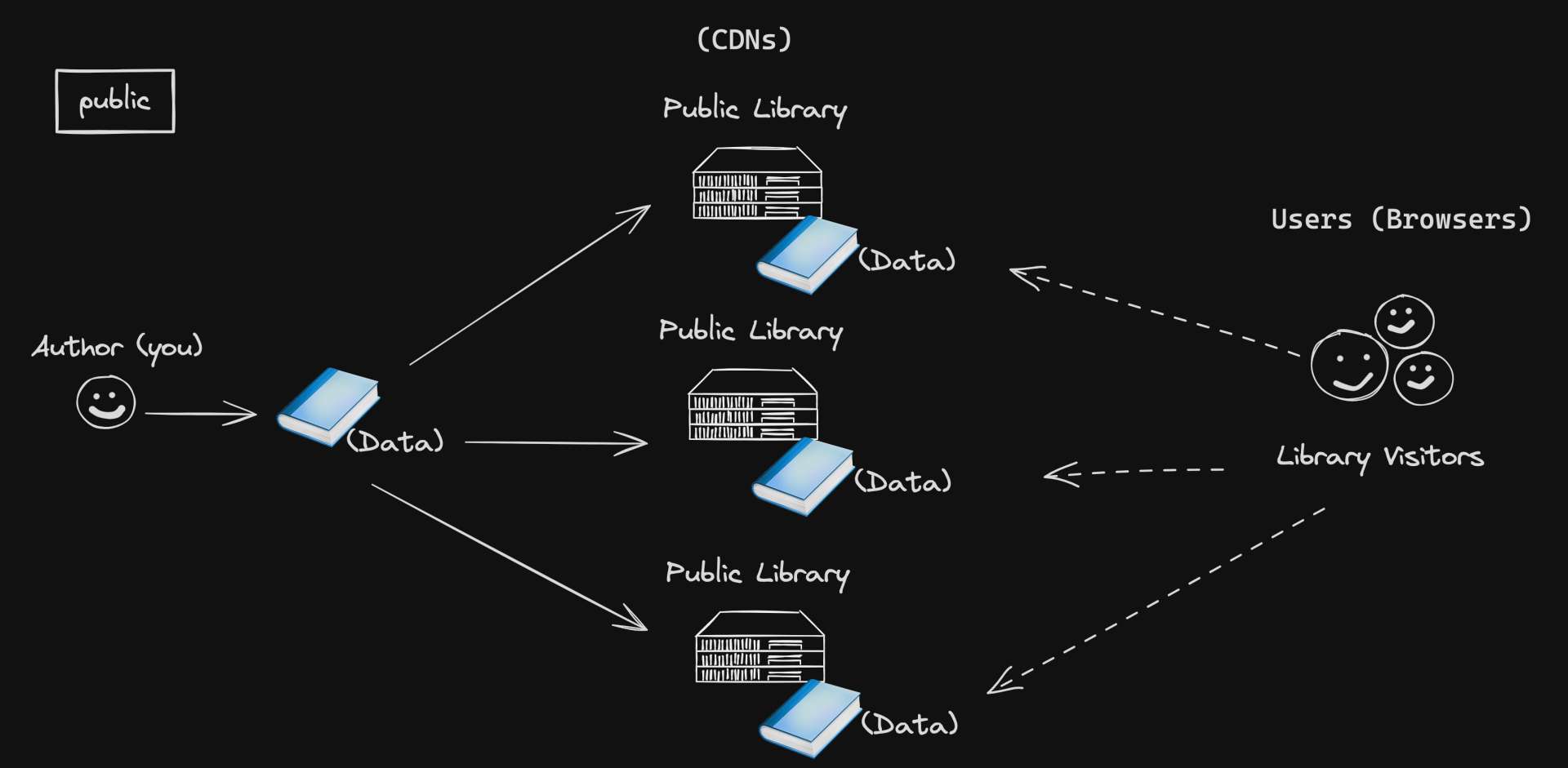
Anyone can come and read it. It's available to all.
In the same way, public means any cache (like a library) can store the data (like a book) and give it to any user (like a library visitor).
__
private: This is like a book that you've checked out from the library.
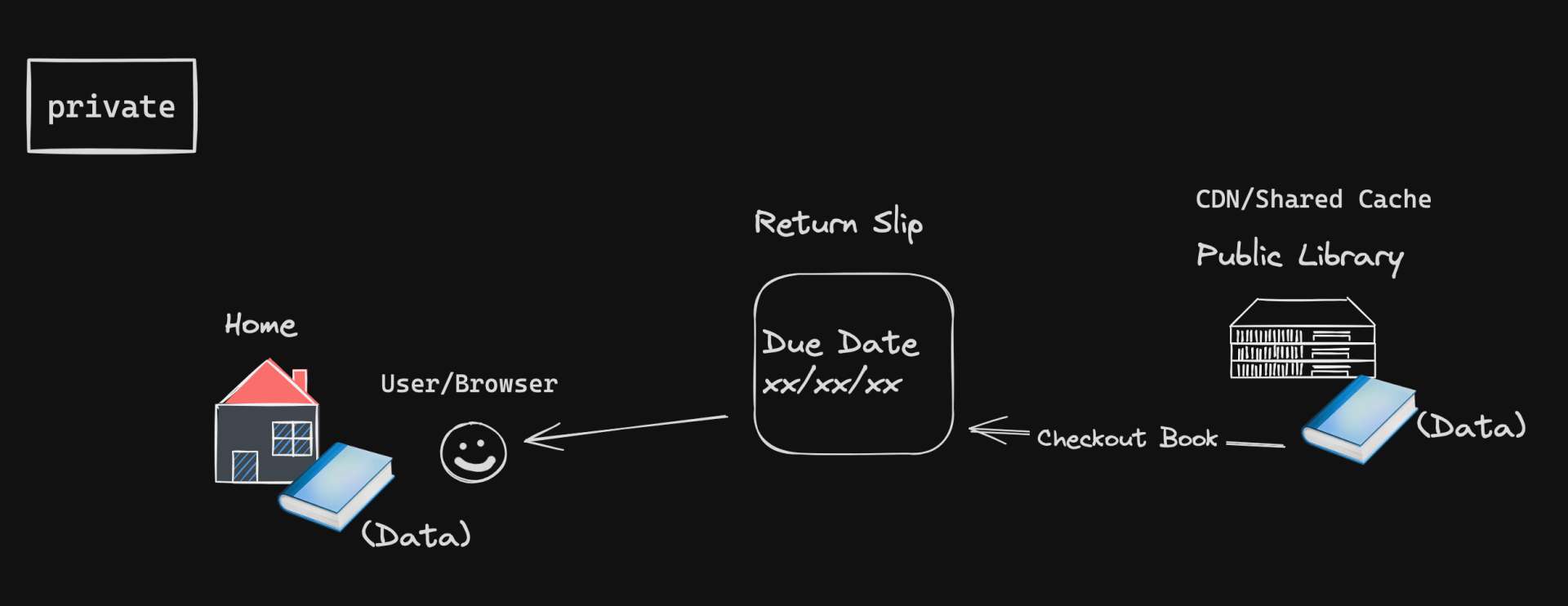
Only you can read it until you return it.
Similarly, private means only your personal cache (like your personal bookshelf) can store the data and it's only for you (the browser cache).
__
no-store: You can think of this as like a rare book in a library that you're allowed to read, but can't check out or photocopy.
You can read it once, but you can't store it anywhere.
Think of it as a library's collection of antique books, manuscripts, first editions, or books with special historical significance.
Similarly, no-store means the data can't be stored in any cache. It can be sent to you, but it can't be stored for later use.
Exploring Cache Headers
So, the next thing you might be wondering is:
How can I instruct the browser to cache my resources effectively?
Caching Instructions
When the browser fetches a resource from the server, it reads the Response Headers from the web server. These are the instructions that dictate how to cache the resource.
Let's start by taking a closer look at the web server.
__
Picture the flow on the left side of the dashed line in this diagram:
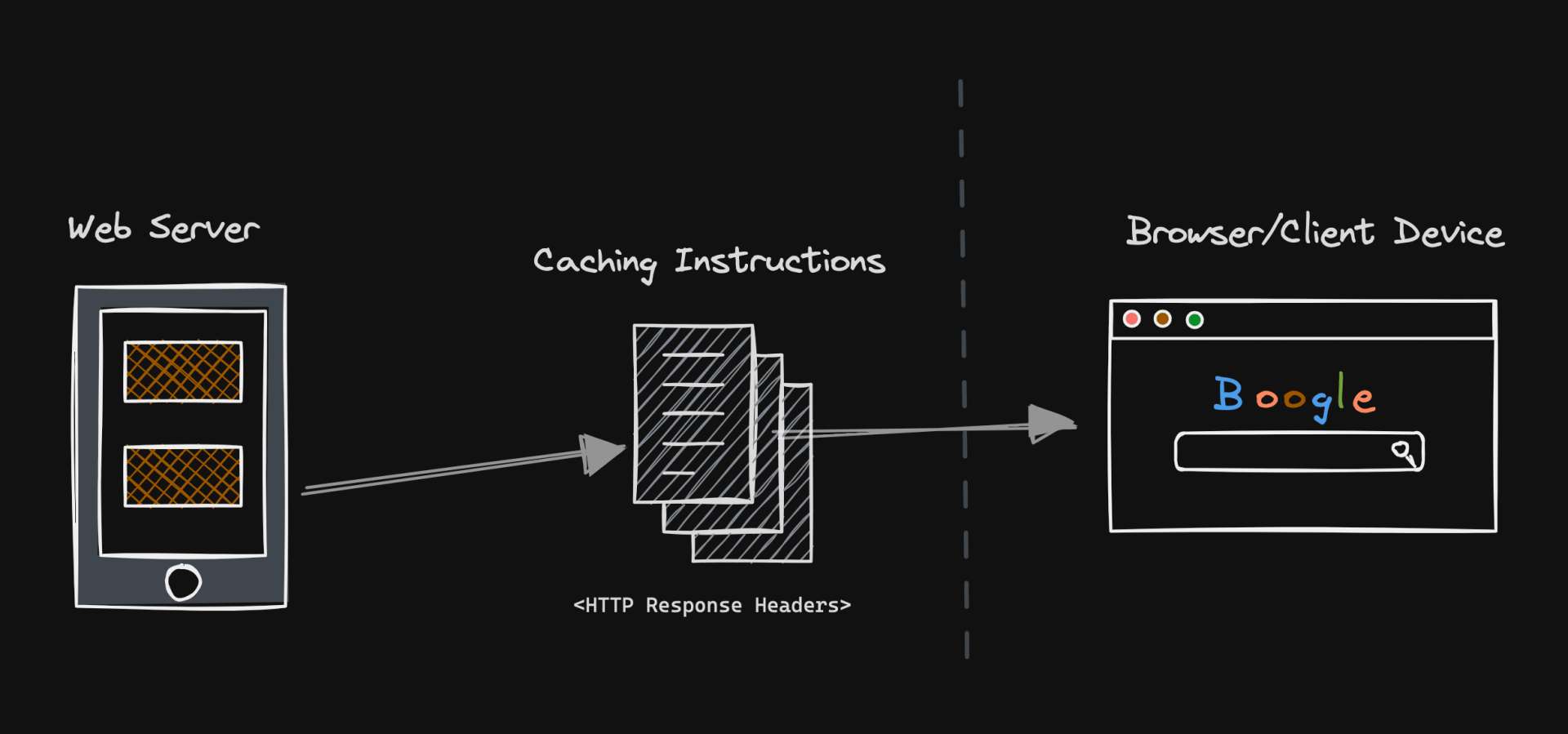
The most crucial aspect of the HTTP caching setup is the headers that your web server attaches to each outgoing response.
These headers can be thought of as the "rule book" for your browser, telling it how it should cache a resource. Inside of the "rule book," are instructions made up of common Cache Headers for effective caching:
Common Cache Headers
| HTTP Header | Description |
|---|---|
Cache-Control | Controls how and for how long the browser caches resources, and specifies the behavior for cached resources. |
ETag | Provides a unique identifier for a resource version, used to check if the resource has changed since the last request. |
Last-Modified | Indicates when the resource was last changed, used with If-Modified-Since to decide whether to fetch the resource from the server or cache. |
These are just the most commonly used headers!
There are several more HTTP headers that are related to caching that are worth reading about.
ELI5 Explanation
Let's revist our library analogy from earlier and put yourself there. This library is like the server where all the website's files are stored.
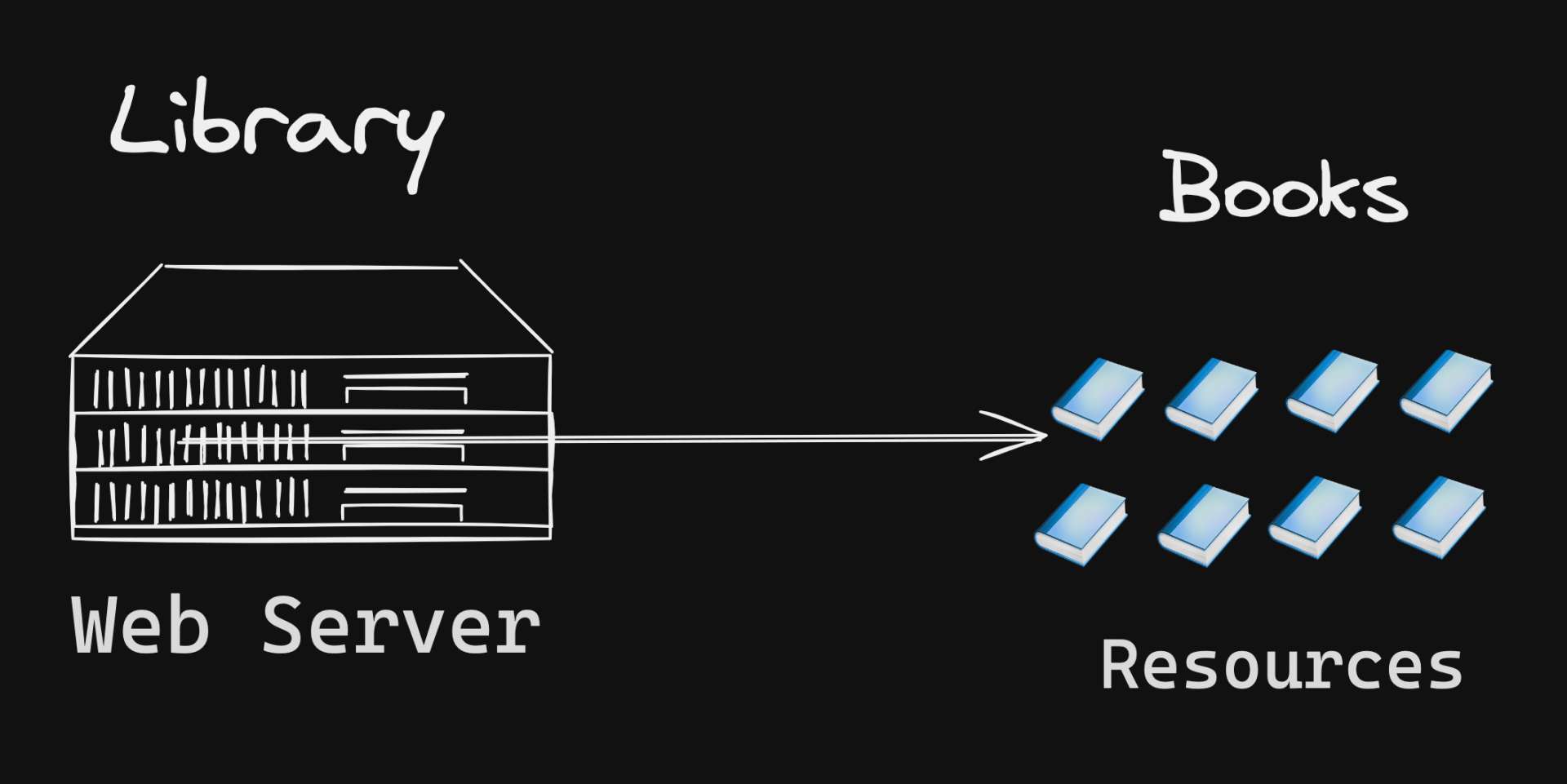
__
Now, meet our librarian.
The librarian is like the Cache-Control header. They tell you the rules about borrowing books.

__
Now, our librarian has a list of rules for borrowing books.
This list is like the Cache-Control header's directives.
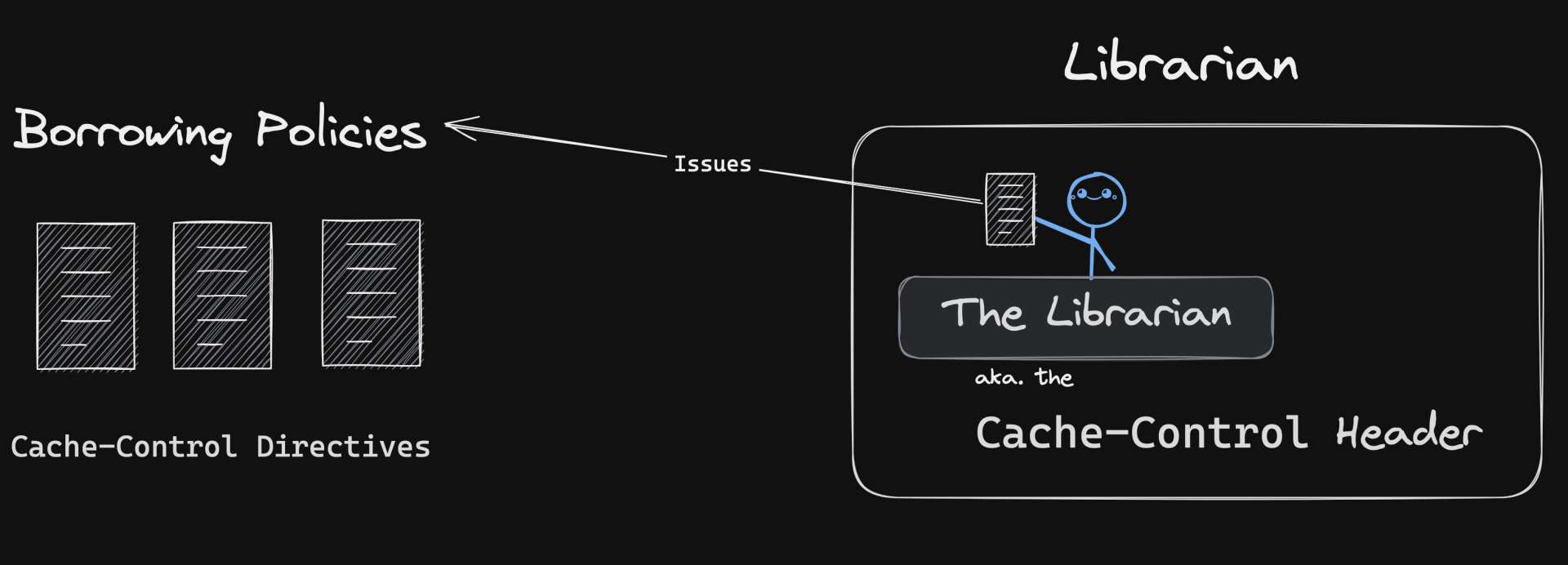
It tells you how long you can keep a book, which books you can't take home, and when you need to check if there's a newer edition of the book you're reading.
The note says:
| HTTP Header | Description | Library Analogy |
|---|---|---|
cache-control: max-age | This directive tells the browser how long it can keep a file before checking back for a new one. | "You can keep a book for two weeks." |
ETag | Provides a unique identifier for a resource version, used to check if the resource has changed since the last request. | "Check the book's unique library code to see if it's the same one you borrowed before." |
Last-Modified | Indicates when the resource was last changed, used with If-Modified-Since to decide whether to fetch the resource from the server or cache. | "Check the date on the back of the book to see when it was last updated." |
Setting Cache-Control Values
When it comes to caching, one size does not fit all. Different types of resources on your website can and should have different Cache-Control settings.
Cache Duration
In the Cache-Control header, max-age is used to specify the maximum amount of time that a resource will be considered "fresh" relative to the time of the request:cache-control: TTL
The optimal cache duration for your resources depends on your specific needs and how often your content changes.
However, there are several types of resources that typically don't see updates often, making them good candidates for longer cache durations:
Here are some Cache-Control values to get started:
| Resource Type | Suggested Cache Duration | Description |
|---|---|---|
| Images | public, max-age=31536000, immutable | Images are cached for 1 year and won't be revalidated because they rarely change |
| Stylesheets (CSS files) | public, max-age=604800 | CSS files are cached for 1 week and will be revalidated after that period |
| JavaScript Files | public, max-age=604800 | JS files are cached for 1 week and will be revalidated after that period |
| Fonts | public, max-age=31536000, immutable | Fonts are cached for 1 year and won't be revalidated because they rarely change |
| Downloadable Content (PDFs, ZIP files) | public, max-age=31536000, immutable | Downloadable content is cached for 1 year and won't be revalidated because they rarely change |
| Favicons | public, max-age=604800 | Favicons are cached for 1 week and will be revalidated after that period |
Static Assets
Static assets, like scripts, stylesheets, and images, don't change or generate on request. Tools like Vite handle these by allowing placement in the /public folder. This bypasses Vite's bundler, useful for large assets or files like robots.txt or favicon.ico that need root path serving.
And here's a diagram showing how these files are processed in the bundle output:
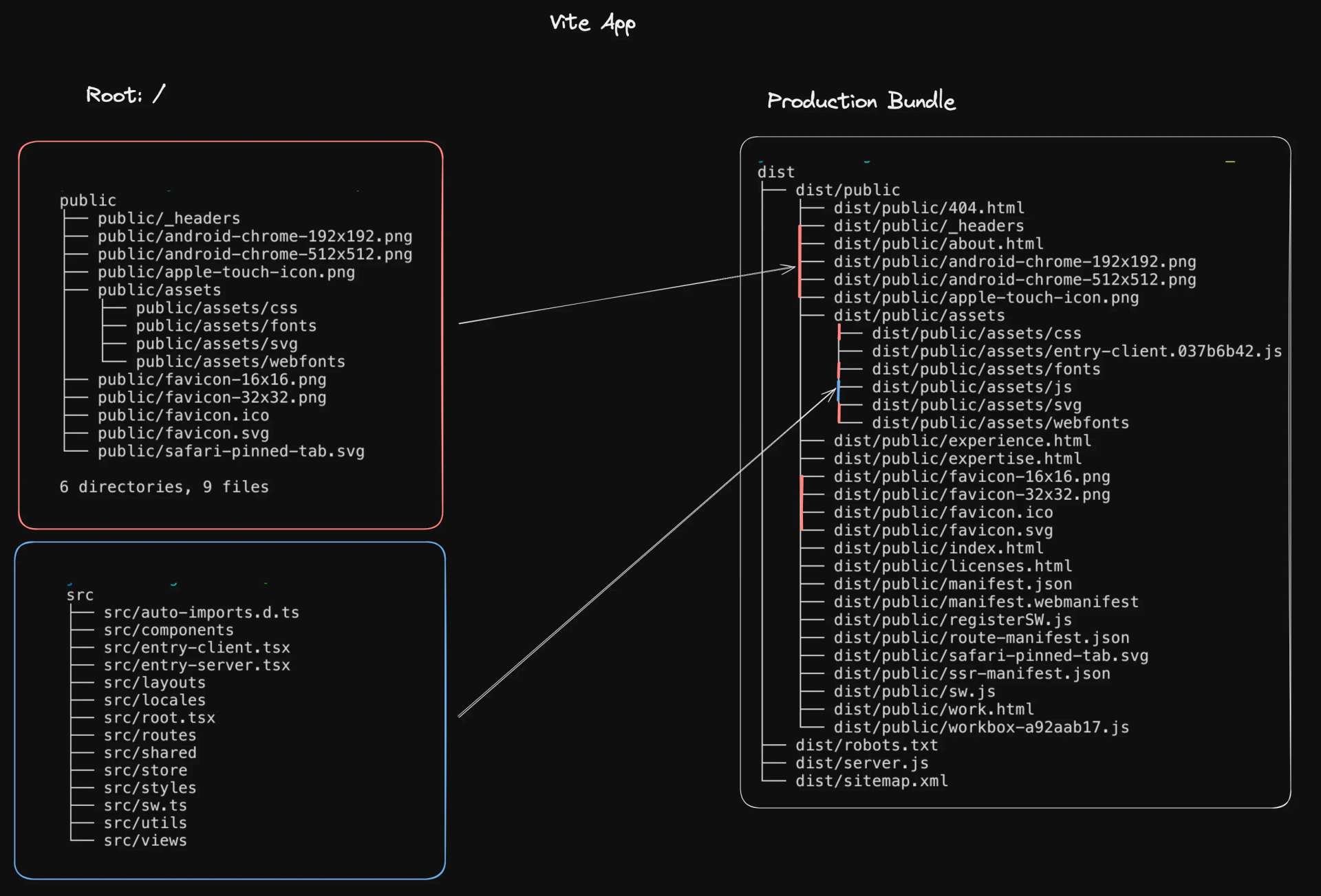
Static assets in Vite's /public folder aren't processed by the bundler but are included in the production build. This ensures necessary assets are available in production and, with appropriate Cache-Control headers, served efficiently.
You can manage asset caching with Cache-Control headers, dictating browser cache duration.
Most CDNs, including Netlify, allow header configuration. With Netlify, you use a _headers file in the site's publish directory:# Example configuration in a _headers file
# https://docs.netlify.com/routing/headers/
/*
cache-control: public,max-age=300
# eg. Fonts rarely change so cache for 1 year
/fonts/*
cache-control: public,max-age=31536000
/favicon.svg
cache-control: public,max-age=31536000
Stale Cache
So, now you started caching files to speed up your site. But...
What happens when those files change on the server? How does your browser know to get the new version?
This is where we run into the concept of "stale cache".
Let's take Netlify as an example. Netlify's CDN uses the following response headers when serving resources:cache-control: public, max-age=0,must-revalidate
Here's what it really means:
max-age=0: This tells the browser to consider the cached file as immediately stale. In other words, as soon as the file is cached, it's already considered out of date.must-revalidate: This tells the browser that once the cached file is stale (which, remember, is immediately), it must check with the server before using that cached file.
So, instead of "never cache this file", max-age=0, must-revalidate actually means "cache the file, but always check with the server before using the cached version".
Alternatively, you could use no-cache:cache-control: public, no-cache
This directive is a bit more straightforward. no-cache simply tells the browser to always validate the cached file with the server before using it, similar to max-age=0, must-revalidate.
So, both max-age=0, must-revalidate and no-cache achieve the same goal: ensuring the browser always checks with the server for the most recent version of a file, even if it has a cached version.
The difference is mostly in how they express this directive.
File Versioning
So far, we've explored how caching works, the significance of setting cache durations for static assets, and the concept of a stale cache with the no-cache directive.
Now, imagine this:
a visitor browses your site, and their browser caches a file named /notes.js. You've updated /notes.js and deployed it to the server, but due to caching, users might still see the old version.
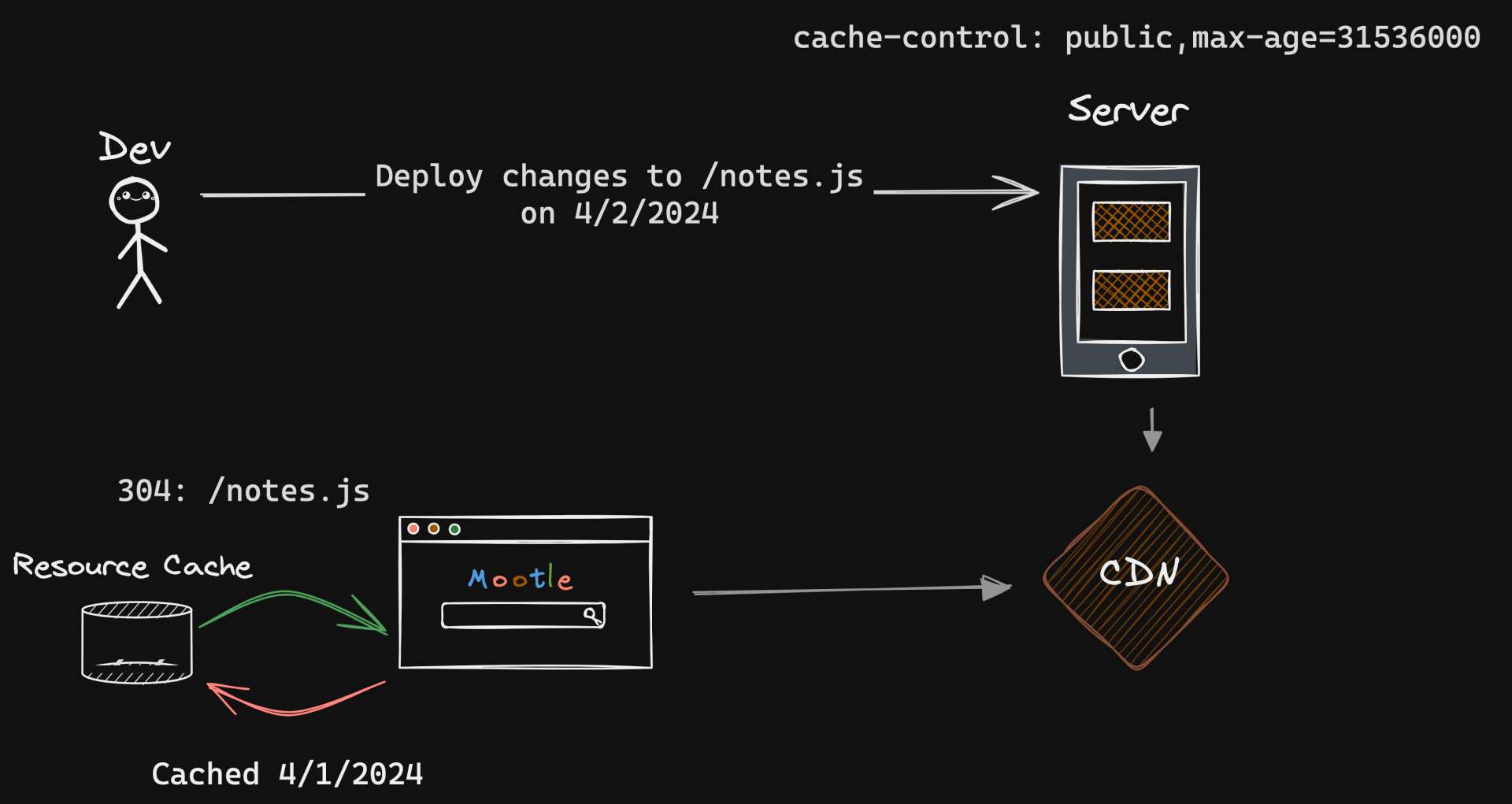
This is where file versioning comes in.

By renaming the updated file (say, to /notes.v2.js), the browser is forced to fetch the new file from the server, bypassing the cache.
In addition to this, it's a good practice to include the immutable directive in your caching strategy:Cache-Control=max-age=31536000, immutable
The immutable directive tells the browser that the resource will never change during its max-age, and that it should not revalidate the cache when serving this resource.
This can save some valuable network traffic and improve performance.
To better understand, let's revisit the Vite bundle files we discussed earlier but focus on the files located in the Refer to image from #Static Assets section for more context/assets/js/* directory: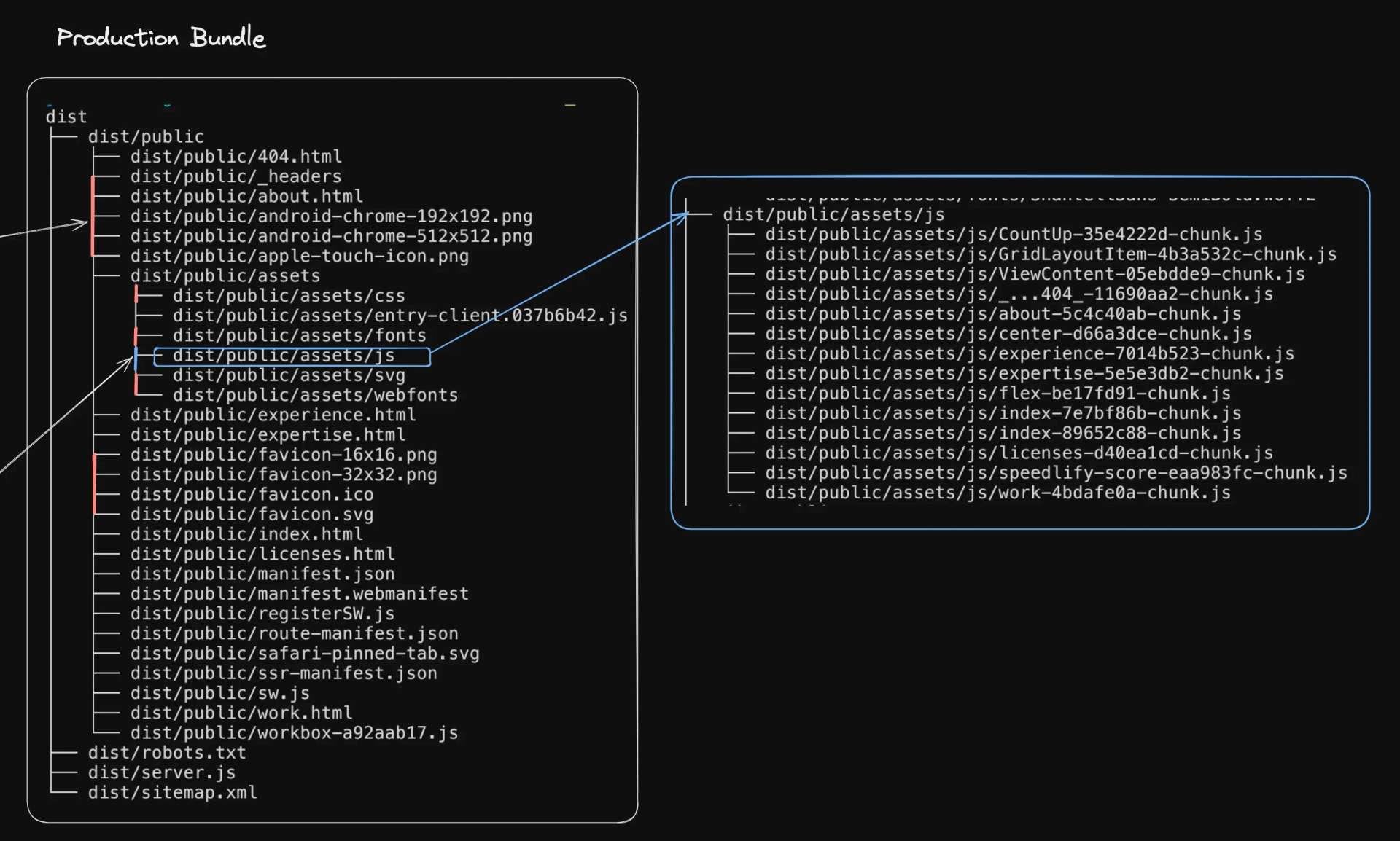
This diagram illustrates how Vite handles the build process, generating a bundle of static files. You can see that each file has a unique hash in its name. This hash changes whenever the file content changes, effectively implementing file versioning.
By customizing the assetFileNames and chunkFileNames in from Vite build options, we can control how the filenames are generated during the build process./* vite.config.ts */
export default defineConfig({
build: {
assetsDir: assetDir,
// ...
rollupOptions: {
output: {
assetFileNames: processAssetFileNames,
chunkFileNames,
},
},
},
})// config/assets.ts
import type { PreRenderedAsset } from 'rollup'
interface AssetOutputEntry {
output: string
regex: RegExp
}
export const assetDir = 'assets'
export const chunkFileNames = `${assetDir}/js/[name]-[hash]-chunk.js`
const assets: AssetOutputEntry[] = [
// ...
{
output: `${assetDir}/js/[name]-[hash][extname]`,
regex: /\.js$/,
},
// ...
]
export function processAssetFileNames(info: PreRenderedAsset): string {
if (info && info.name) {
const name = info.name as string
const result = assets.find((a) => a.regex.test(name))
if (result) {
return result.output
}
}
// default since we don't have an entry
return `${assetDir}/[name]-[hash][extname]`
}
Web Server Examples
To wrap up, here are a couple of different examples on how you might configure your server's header response depending on your tech stack:
Nginx Example
For a basic Nginx configuration that listens on port 80 and serves static files from the /var/www/html directory:# /etc/nginx/nginx.conf
server {
location / {
# other configuration here...
add_header Cache-Control "public, max-age=31536000";
add_header Vary "Accept, Accept-Encoding";
}
}
Remember to reload or restart the Nginx service after making changes to the configuration file:# Unix / Osx
sudo service nginx reload
# systemd / Ubuntu
sudo systemctl reload nginx
Netlify Example
You can instruct Netlify on how browsers and caches will handle your files directly from the netlify.toml file:# netlify.toml
[[headers]]
for = "/*"
[headers.values]
Cache-Control = "public, max-age=31536000"
Vary = "accept, Accept-Encoding"
Links
Other articles about HTTP headers and caching strategies:
- Caching Header Best Practices - @SimonHearne
- Http.dev - HTTP Caching - @http.dev
- The State of Browser Caching, Revisited - Mark Nottingham - @mnot
- Netlify - Better Living through Caching - @ChrisMcCraw
- Service Worker Caching and HTTP Caching - @Mozilla
- HTTP Caching is a Superpower - @ElliotClyde
- Inline SVG… Cached - @ChrisCoyier